
A marketing site for Datamorphosis, a Data Science start-up with offices in Pune (India), Bruges (Belgium), and San Francisco (US).

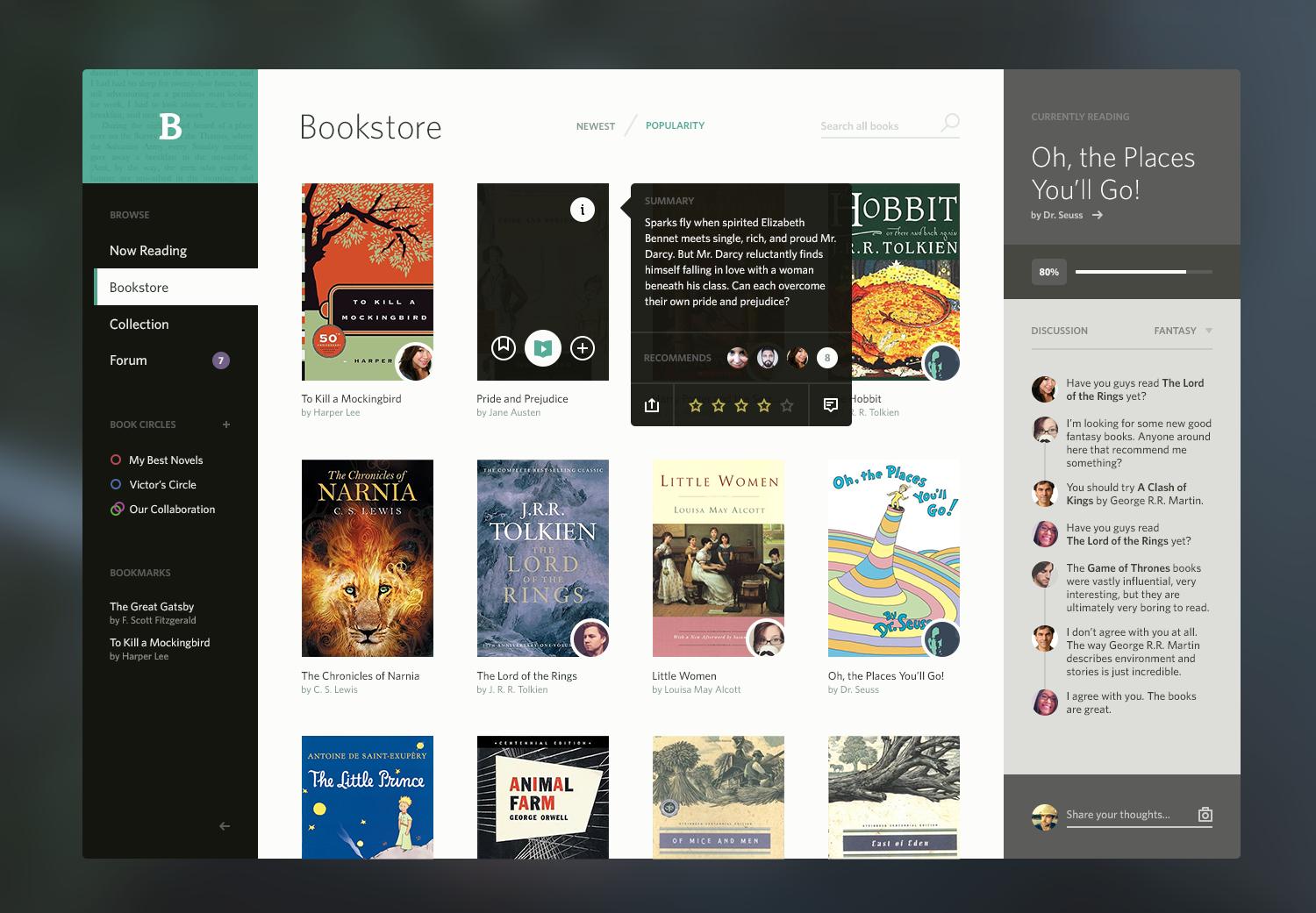
A PoC of creating responsive list view with list items containing metadata which gets reordered and styles are updated depending on available page width. This was originally created to develop a GitLab feature and make it easier to quickly test the UX without having to run entire GitLab instance, see original GitLab Issue.

A JS utility to probe user client for Operating System and Web browser being used and represent it via attribute value of <body> element and in JS via a Boolean flag.

Commits are one of the key parts of a Git repository, and more so, the commit message is a life log for the repository. As the project/repository evolves over time (new features getting added, bugs being fixed, architecture being refactored), commit messages are the place where one can see what was changed and how. So it’s important that these messages reflect the underlying change in a short, precise manner.

Poster is a React + Redux webapp to list Movies (via TMDb APIs) and maintain Watchlist, and my hands-on experience with React and Redux.
GitLab CE Webhook Server or GWS is dead simple Node.js script which can run with minimal effort (and no external dependency) and can monitor events which are provided by GitLab CE Webhooks, and perform tasks (actually a bash/batch script) on those events.
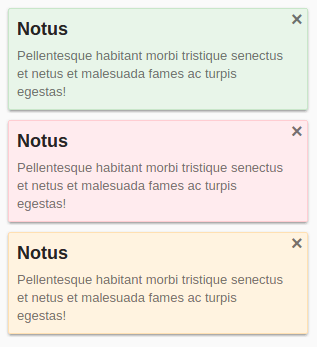
Yet another non-blocking, pop-up notification library for the web, strictly without jQuery (or any other dependencies).

A jQuery Plugin to show collection of images in a collage as flashy boxes.

A loading animation I came across on bestwebsite.gallery, made using CSS3 keyframe animations.
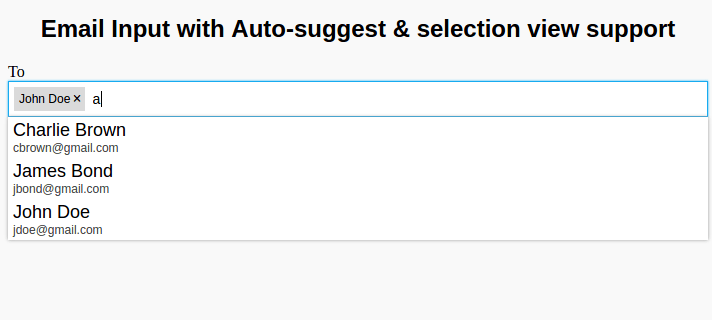
Mail address input box (similar to Gmail/Outlook) with autocomplete and raw mail address input support. In short, it works exactly like Gmail’s To, CC, and BCC fields.
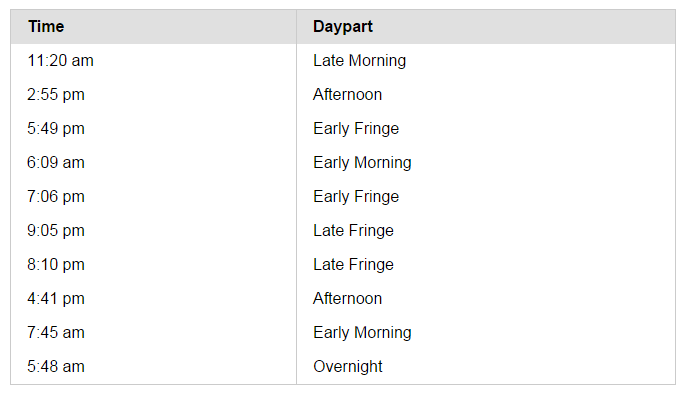
A Dayparting micro library to present time of day in Dayparts.
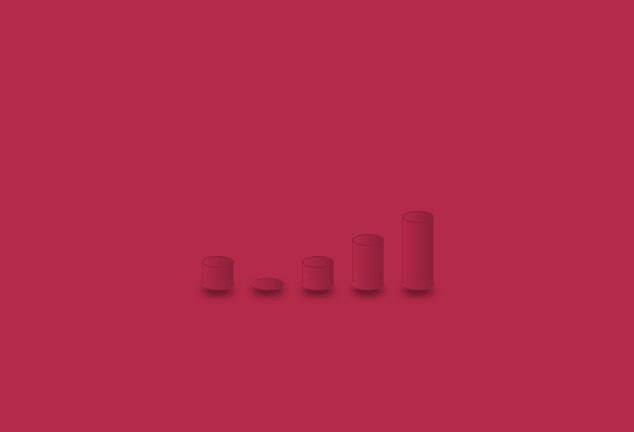
CSS3 Keyframe animation called “Jumpy Pillars” which can be used for your page loaders.
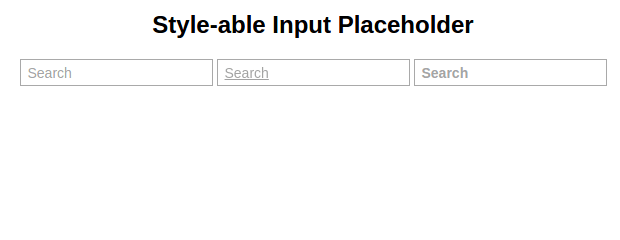
HTML5-ish Input Placeholder that works IE8+ and can be styled by CSS. It uses pseudo element to render placeholder (with HTML5 fallback) and styles are applied on pseudo element itself.

A multi-step progress-bar called “Step-bar” that can be updated just by changing element attributes, using SASS.
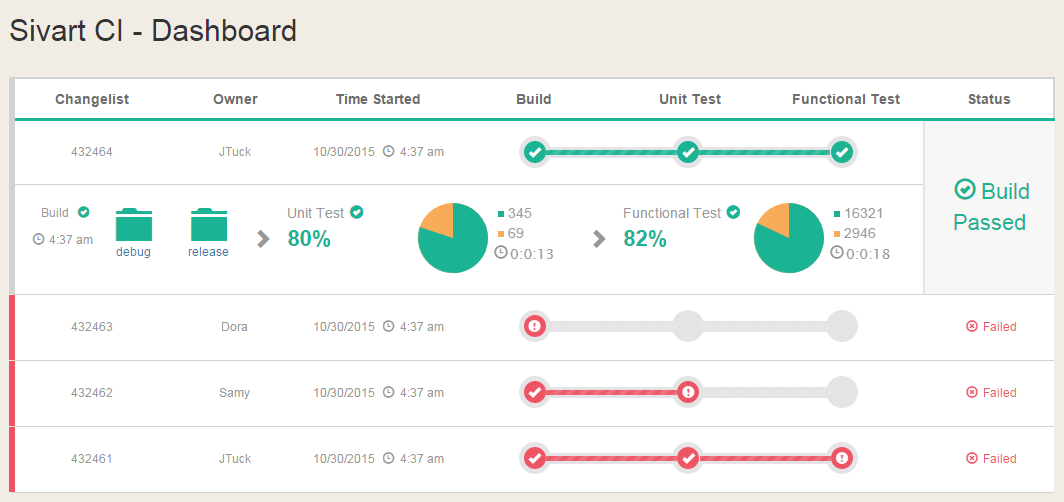
A Body-less Head-only CI Dashboard built with MEAN stack and Socket.IO for Realtime monitoring.

Back in the year 2003 when Android, Inc. was co-founded by Andy Rubin (with Rich Miner, Nick Sears and Chris White), which was later acquired by Google in 2005, Google formed the Open Handset Alliance together with device manufacturers like Samsung, HTC and Sony and carriers & chipset makers like Sprint, T-Mobile, Qualcomm and Taxes Instruments. The goal was simple, to create an open set of standards for mobile that any device manufacturer can adopt. Android was the first product that OHA announced; a mobile operating system based on Linux.

Last week was Apple’s week as it unveiled series of surprises for users and developers alike, in its annual developer conference WWDC. While most of us had our “oh-aah” moments seeing the grand unveil of macOS Yosemite, the 10th update to the OS X, and iOS 8, a more or less an incremental update to iOS 7, if we ignore the number for a moment. Some of us saw the event as a platform to brag about how innovative Apple is (or was ?) and very next moment showing off features stolen from competitors. Though the biggest surprise that came with this year’s WWDC is that it finally became a Developer Conference in its true sense.
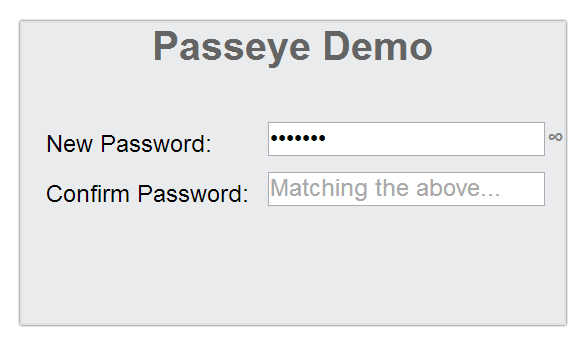
Passeye is a jQuery Plugin that converts regular password input fields into an input with one-click quick password reveal toggle for usability while keying in passwords.

Analyst 2.0 is a complete rewrite of original Analyst Windows app. Second major release of Analyst is entirely rewritten in C#.NET 4.0 and thus overcomes most limitations that first version faced.
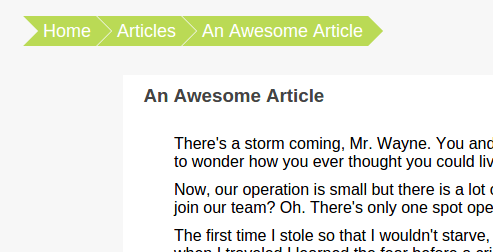
Navigation breadcrumbs with clickable crumb items.
When it comes to Humans, interacting with computing devices, the friendship is slightly more than two decades old. From the flow of endless text in black and green colored hypothetical screens to amazing designs of today spread across any screen size you can think of, Graphical User Interfaces have come a long way on the only available canvas; Screens.

A fictional happy face inspired from Lea Verou’s CSSConf 2013 presentation Though it is not a perfect replica, but it is cuter. Original presentation slides available here.

A CSS filters demo showing how image colors can be manipulated purely using CSS. Social icons on-hover grayscale effect with CSS3 filters applied and with no filter applied.

The Dark Knight logo with all-CSS circles and edges.

Its been a year since I’m using GitHub and all I have to say is, how the hell I was able to code earlier! Too loud? You may reconsider after reading the entire article. Unlike my earlier posts, this post is for programmers ( and also my first brief tutorial).

Let’s set up some grounds before I proceed, and shift ourselves back in early, early Nineties of Technology. WWW was the-next-big-thing, getting “online” was cool. More than 50% of the first-world nations (as they like to call themselves) had internet access. People started spending more time in chat rooms within their own rooms, thanks to AIM and ICQ. IRC (Internet Relay Chat) was every nerd’s underground of dark discussions. Computers left laboratories and entered living rooms.

Press has put mixed responses over Facebook Home, some say its an incredible leap of Facebook in mobile space while some say it is a disaster. Some users complained Facebook to stabilize existing facebook apps for Android and iOS first, rather than working on newer products. But Facebook Home is indeed more than just an App, a launcher or Facebook Phone as some name it.

Just before two days Google announced that it is forking WebKit for using in its Chromium open source web browser (thus, everything that follows it, Chrome, Chrome OS, Android Browser and others ), naming it Blink. This initiated a great round of talks all over the web on how it’s going to change Chrome, and other browsers in general. So I decided to write a blog post (and probably the first ever blog post of mine) on this.
A CSS3 animated Windows 8 logo, using CSS3’s @keyframes animation with transform and perspective properties.
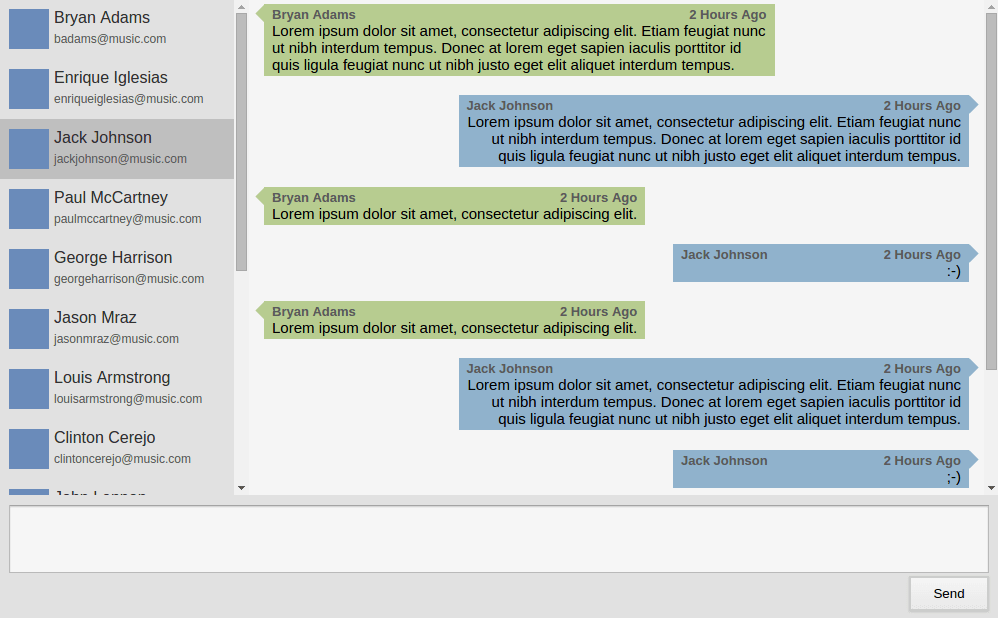
A Chat View design made purely in CSS, can be adopted for any chatting service for the web (recently WhatsApp for Web adopted similar design).
CommonUtils is a utility library for Java which provides common set of functionalities that are required in most of the web applications. Functions include; plaintext/file to hash-code generation, validating form fields, generating random CAPTCHA challenges, and many other stuff.

JSONify is a minimal (only 437 bytes!) HTML-form to JSON to HTML-form converting plugin for jQuery. It creates JSON string from the name-and-value pair of form fields, and can perform JSON to form initialization.
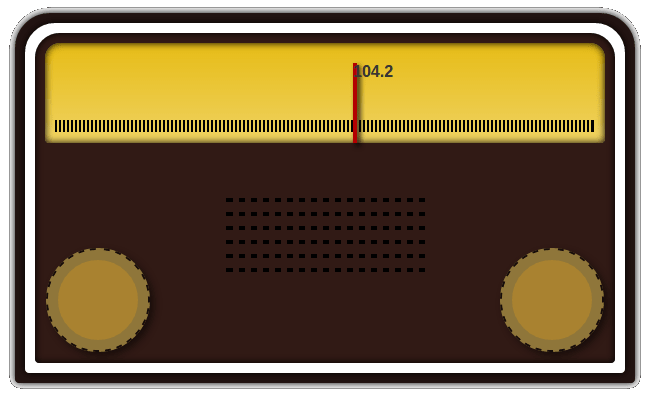
A Retro Radio created using only CSS, a simple 2 hour experiment to know CodePen’s demonstration abilities.

DroidBridge is a digital version of popular cards game Contract Bridge, for Android (2.3.3 or higher). It is used to play the game with three other players having it installed in their Android device, once they all connect with DroidBridge Game Server. The app communicates with DroidBridge Game Server over Java Socket. Data exchange between client and server takes place in JSON format and follows DroidBridge Communication Protocol v1.0.
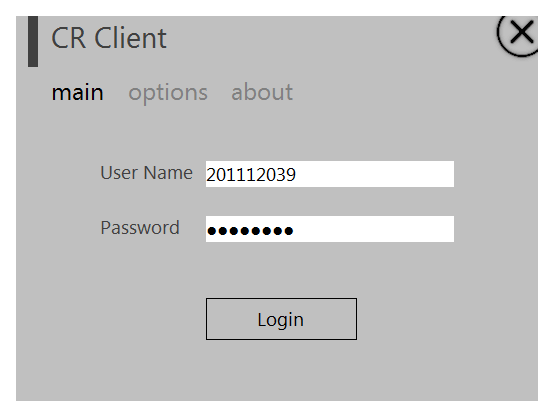
A modern-designed Cyberoam Desktop client for Windows with support for auto-login, desktop notifications and user-name/password saving. The project was done in Visual Basic.NET 2010 over a weekend to fix the limitations we faced while using browser login portal of Cyberoam in our college network.

A scientific Windows application for Parshva Diesels Pvt. Ltd. developed to assess performance of Diesel Engines as per ISI standards. The project was created in Visual Basic 6.0, and made use of several Windows APIs instead of just limiting itself to VB6’s limited capabilities.