Co-doing it right with GitHub
May 29, 2013
Its been a year since I’m using GitHub and all I have to say is, how the hell I was able to code earlier! Too loud? You may reconsider after reading the entire article. Unlike my earlier posts, this post is for programmers ( and also my first brief tutorial).

DISCLAIMER: This article is not a brief tutorial on Git Version Control System (or VCS in general), there are many places on web where you can learn it from beginning. Instead, I’ll be focusing here on GitHub (with some parts of Git, obviously) and how to make it work for your next project.
Git and GitHub - a Primer
Git is a distributed version control system, distributed in a sense that many developers (irrelevant of their location) can work on same code, since there is no central server where developers have to push or pull the changes. It was created originally created by Linus Torvalds (yes! same Linus who created Linux) primarily for using it as VCS for Linux Kernel Development. Git is open source and fairly easy to learn and use, so it became popular over the course of time and currently large number of projects use it (including Android, Chromium, and many more).
Now, GitHub is a service built on top of Git. It adds the social capabilities to Git which makes it easy for many developers to work on a common project. It hosts all your code in a public repository which then can be shared with the world. Developers can collaborate on a project or they can fork a repository and contribute to the project. So, you get the point here? GitHub is more about “socially coding”, of course you can keep your code private as per your needs.
Let’s Start!
You can sign-up on GitHub for free and get virtually unlimited number of repositories and unlimited collaborators. While Git is all about command-line stuff, there are nice Windows and Mac apps (Linux users, you’re already awesome!) that can take care for most of the work for you via a decent GUI. But, we’ll do our stuff here on command-line as its fast and you have more control.
Creating a Repository
Creating a repository in Git is a matter of running following commands in terminal; git init followed by git add . within your
project folder that you want to track, but creating a repository in GitHub is not a command-line stuff. There are two ways
you can follow, first create a repository locally using standard Git commands and link it to online GitHub repository,
or doing it in reverse, creating an online repository first and then clone it in your computer and add your files.
In either of the ways, you need to create repository on GitHub via its web interface. I’ll cover the second way,
which I believe is the ideal approach.
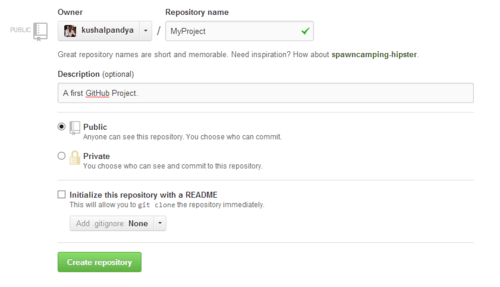
You visit your GitHub homepage (the https://github.com/<your user name> URL) and create a repository from “Repositories” section
with “New” button. Give a unique name to your repository and hit “Create Repository”, in my case I’ve given it “MyProject”.
There’s an option to check called “Initialize this repository with a README”. README files in Git repository are usually
markdown-formatted files (with .md or .markdown extension) which are shown
when your repo’s page is visited on GitHub. You may want to check this option while creating repository and add some
description for your project in the README file later (It’ll have your repo’s name and added description by default).
Once the the repository is created, you’ll be presented with a page showing your code and README file’s description.
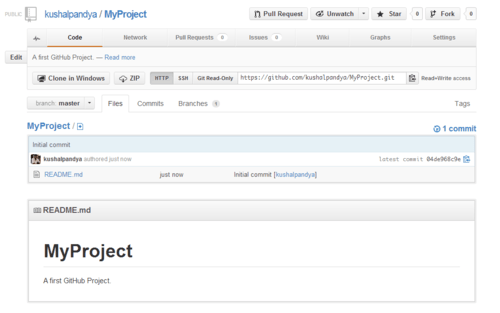
On this page you get an HTTP and SSH URL of your repository which you can use to manage your files on repository on GitHub.
If your network allows SSH access (and if you prefer more raw access to your repository online), you can click on SSH button
and get the URL, otherwise HTTP URL is enough to get things done. In our case it is https://github.com/kushalpandya/MyProject.git,
copy the URL and open the terminal (if you’re on Windows you can use your GitHub app to clone the repo, it’ll automatically
show it) and run to clone entire repository into your hard-drive.
git clone https://github.com/kushalpandya/MyProject.git
It’ll start cloning your repository within your current working directory and copy all the files and folders in it (for MyProject, there’ll be only README.md file). Once all the files are cloned from the repo, you should see it in your current working directory under “MyProject” folder.
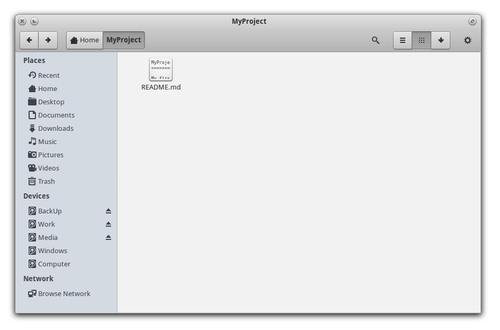
As you can see, we have only “README.md” here. Now, we want to add something to this repo, here’s a lesson, the true power of Git comes with a concept of Branches, think of a branch as a shadow copy of the entire repository where you can add changes to a single branch which won’t affect other branches.
Every Git repository has a main branch known as “master”, this branch is considered as highway where only stable and final code should be kept. Now considering above example, by default we have only master branch here which has only single file “README.md”, now we want to add a new file to this repo, but we don’t want to make these changes directly into master, remember, every time you start working on a new part or functionality of your project, DO NOT make those changes into master branch, always, always create new branch first and then proceed. So let’s create a new branch using following command.
git checkout -b feature/HelloWorldProg
The above command creates a new branch called “feature/HelloWorldProg” by copying everything the repository has in its master branch (it doesn’t actually copy all the files, remember, Git doesn’t track real files, it tracks content within the files). It made new branch out of master because we’re currently working within master branch. So what’s the catch here? Git always creates new branch from current branch that you’re working on when such command is run.
Now the Question Arises, How to Name a Branch?
Short answer: Be concise, clear and short with branch name.
Long answer: Naming a branch properly is extremely important as once a project starts with its full course development and
you begin to create many branches in your repo, not having a concise name will leave you wondering what code exists in which
branch. What I follow? If I’m working on a new feature for a project, I prefix branch name with feature/ followed by actual
feature name (slashes are allowed in branch names). If I’m working on a bug fix, I prefix my branch name with fix/ID, where
ID is the issue number that I’m working to fix (learn more about bug-tracking on GitHub later in this article). But you can have
your own naming conventions for the branch. In fact, there’s a great discussion on
Stack Overflow regarding the best practices followed
in naming Git branches. You can read more on what’s allowed syntactically for a branch name in Git
here. Also, concept of Branching and Merging them
(yes, you can merge branches in Git, more on that later) is vast and beyond the scope of this article, but you can refer to
this excellent guide on the same which will help you
understand just that.
If I’m working on a new feature for a project, I prefix branch name with
feature/followed by actual feature name (slashes are allowed in branch names). If I’m working on a bug fix, I prefix my branch name withfix/ID, where ID is the issue number that I’m working on to fix.
Now back to our example, upon running the command, it just creates a new branch called “feature/HelloWorldProg”, but we’re still
active on our master branch, so in order to start working in a new branch, we can run git checkout feature/HelloWorldProg, this
will switch to our newly created branch. You can create a new branch and immediately switch to it by running
git checkout -b feature/HelloWorldProg instead of running two commands as we did earlier. Since we’ve created a new branch
from master, there’s no difference for now, it’ll have the same README file. Now let’s add a new file called HelloWorld.c to
our project.
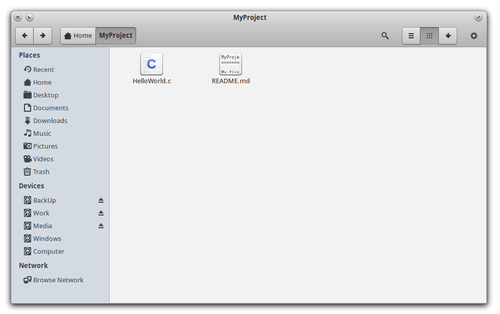
Since we added the file, you can go back to terminal and run git status, this command will show you that you’ve just added a new
file in your feature/HelloWorldProg branch which is not currently tracked by Git.
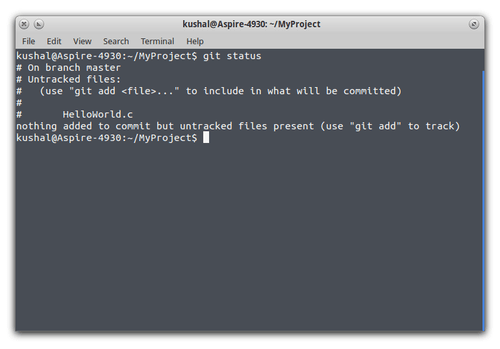
In Git, before it can track any file, we need to add that file to the repository first, just keeping it in folder is not enough.
So let’s add it by running git add HelloWorld.c. This will add the file to our newly created branch. Now let’s commit the
changes we’ve made using following command.
git commit "HelloWorld.c" -m "Hello World program added for C Language"
Above command commits the newly added file to the branch with the message (called, commit log). Another lesson,
be wise with commit messages you give, don’t be overly verbose or highly brusque. You can have longer commit messages,
but instead of writing everything in detail, be concise with the message and include what’s essential in the commit.
As we commit the changes and run git log we’ll see list of all the commits that have made so far in the branch (note
that we’re still working in feature/HelloWorldProg branch).
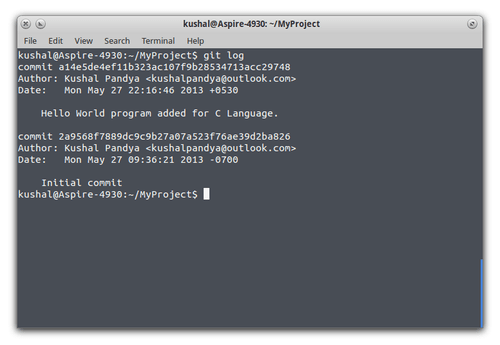
Observe that there’s one another commit with message “Initial commit”, this was made by GitHub when repository was created and README file added to it, being very first commit to repository. And remember, you cannot switch between branches until your current branch has all the changes committed. Now that we’ve completed the feature we were working on, it’s time to push the changes back to our online repository on GitHub.
Before I proceed with it, let us understand the concept of “remote” in Git. Since Git is a distributed VCS, there’s no
central server involved where all the code is placed, rather, we can have remote repositories which are “linked” to our
local repositories. They can act as our backup with all branches and commits intact. Remote repositories can be linked
to our local ones with a URL, and that URL is identified via an alias. Since we cloned MyProject from GitHub into our
hard-drive, our local copy of MyProject is already linked with its GitHub URL (remember https://github.com/kushalpandya/MyProject.git?),
since git clone does that for us while cloning the repository. And that URL has an alias already set called “origin”. You can
check it by running git remote -v see the remotes available for this repository.
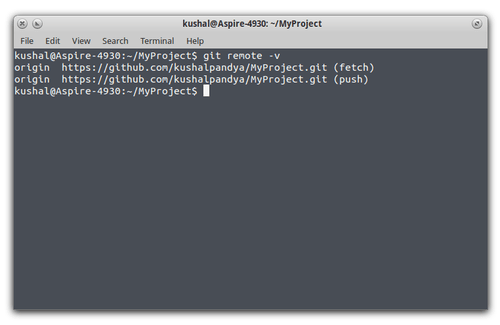
It shows we have same URL for origin with “fetch” and “push”. These are actions available for that particular remote
suggesting that we can push (upload) the changes we make and also can fetch (download) the changes from the same online
repository. You can add as many remotes as you want, each with unique alias using command git remote add followed by its URL.
Note that while you can fetch from any Git remote (if it is accessible to everyone) you may not have rights to push to it,
since a remote URL gives you access to master branch of the remote repository (and master branch is not available for everyone
to write into).
Coming back to our example, let us now push our changes (the new branch that we created) back to our online repository at GitHub using following command.
git push origin feature/HelloWorldProg
It says to Git that, push branch “feature/HelloWorldProg” to the URL with alias “origin”. Once upload is performed, you can go to your repo’s page and see in the branch dropdown that new branch got created.
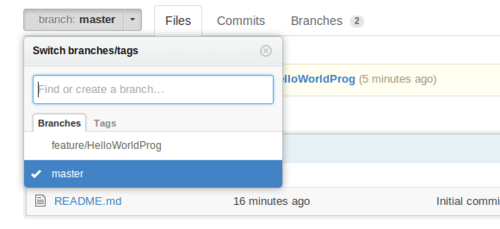
Selecting this branch will show you the file that we’ve added. Remember, we didn’t make any changes in the master branch, so file is only shown in the branch we created.
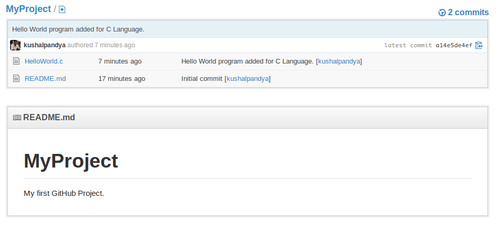
So, we’ve successfully created branches and synchronized it online. But, GitHub is all about working in teams and so far in the example, we only saw how to work individually, so let’s jump into the most powerful feature of GitHub, Forking.
Forks
When a repository is created in GitHub, it is by default public, and anyone can view its code and all commit activities that have took place. And one can fork such public repository into his own GitHub account using “fork” button available at the repo’s page. What happens in this case is that an entire repository is cloned into another account with same name, everything in “master” branch of the repository is cloned. Once a repository is forked, you’ll see it available into your own GitHub homepage, with same repository name. It’ll also have similar URL available, which you can use to clone it back into your hard-drive just like we did in our example earlier. You can then start working into your own fork of the project.
But how to contribute to the original author of the repo? Well, that’s what forking is intended for. When you fork a repo, you get your own master branch of the same repository (with everything that existed in the master branch of original repository at the time of forking). Whenever you’ll make any changes to your own fork or project and commit it, an option called “Make Pull Request” will appear on your repo’s page. Pull Requests are the real magic behind all collaborative projects on GitHub.
Pull Request
So, you’ve forked a repo, you have all its code and now you want to add your own code to it such that it becomes a part of the original repository you forked from. That’s what pull requests does. Whenever you have changes in your own repository (which are committed of course) that differ with the code on original repo, GitHub will show you an option to make a “pull request”. Upon clicking it, you’ll see following page.
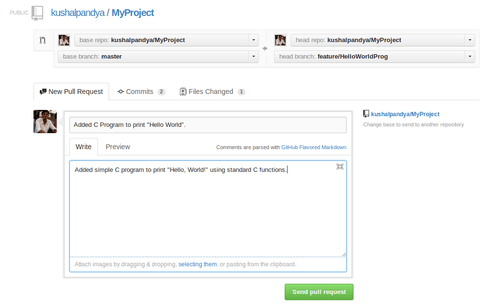
Note that for demo purposes, I’m showing you pull request dialog on same repo, otherwise, on the left you’ll see branch or the original repository and on the right you’ll see your repo’s branch. In the pull request dialog, you need to specify about the changes that this pull request will bring with it. Again, be clear and concise here too. Now, when you click on “Send pull request”, it notifies the original repo’s author that you wish you merge some new code to the repository.
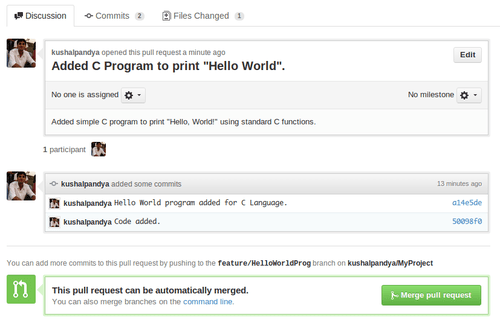
They can then see the difference between his master branch and the code you’re pull request has.
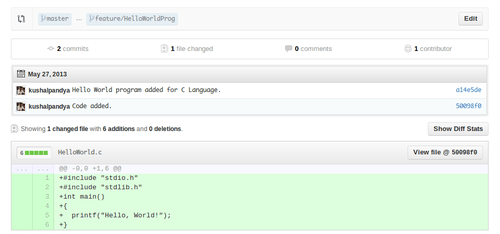
If they thinks that your code is fine, he can merge it, and all your code will be added to original repo’s master branch, cool right? But what if they reject your pull request? And it’ll happen often on large projects. So let’s learn about some basics and best-practices to follow with forking and making pull request.
As mentioned earlier, your fork is exact copy of master branch of original repository (generally called upstream), but by default, when you fork a repository and when changes are made into original repo’s master branch post-forking (new code added after you forked repo), your forked repository gets outdated and will not be synced automatically. And its important to keep your fork up-to-date with upstream, you can do it with remotes, that we learned earlier. As we already know that GitHub adds a remote named “origin” by default to a repo, we do have origin here in our fork too. But, it points to our own fork, not the URL or original repository. So we need to add it manually by following command.
git remote add upstream [original repo URL]
Here you can see that we created a new remote named “upstream” with URL of original repository (usually, term upstream
is used for remote to original repository when it is forked). Once added, you can run git remote -v and see that it
has upstream and its URL available for both, push and fetch. But the catch here is that you technically cannot push
into upstream as you do not have write access to original repository. However, you can fetch from upstream using following
command.
git fetch upstream
It’ll fetch whatever is changed in the master branch of original repo, but remember it’ll not add those changes to your repo, you’ll have to run following command right after above command to see the changes that were made in upstream.
git merge upstream/master
What this command does is that, it merges, whatever is in the upstream’s master branch, into your current working branch (note the phrase “current working branch”). But what if you want to fetch the changes and merge it directly? You can do it with single command (although not recommended).
git pull upstream [branch name you want to merge with]
Above command will first run git fetch on upstream and get all the changes from its master branch, and will try to merge it with the branch name you’ve given in the command (omitting branch name in the command will merge it to current working branch). So basically, it does fetching and merging in a single command. It is more convenient compared to our previous flow but may not be something you always want. I prefer to run git fetch instead of git pull especially on forked projects.
Another important thing to keep in mind while working with forked projects is that never make changes into your own master branch, since it has to stay always in sync with master of upstream. Because when your pull request gets rejected for some or the other reason, your master branch will have changes which do not exist in upstream, and that will cause conflicts (merge conflicts, in official terms) and you’ll no longer be able to sync your repository with upstream. So following is the ideal workflow:
- Run
git fetchfollowed bygit mergeand keep your repository up-to-date with upstream. - Create a new branch in your own repository and work on it.
- Push your new branch on GitHub using
git push origin. - Make a pull request to original repository.
This ensures that your repo’s master branch is never conflicted with upstream. But what if you didn’t follow the above flow and things screwed up? You can’t re-fork the repository and start everything all over again, so what to do? In such horrendous situations, you need to rebase your repository (discard your changes and revert back to upstream”s state). Run following to reset your repository by fetching from upstream.
git reset --hard upstream/master
Note that it just resets your local repo, but we also have to fix our online broken fork, do that using following command.
git push --force
But Why Hard Reset When You Can Always Work With Branches?
In ideal circumstances when your pull request is accepted and merged into upstream, you’ll not only need to update your
fork again using git fetch and git merge (which just updates local repository on your hard-drive) but also need to update
your fork on GitHub by running git push origin followed by branch name (“master” in this case, since you’ve pulled
changes from upstream’s master branch).
Creating and Fixing Issues
GitHub is not only about sharing your code, it has an excellent bug-tracking system available. Users can “create” an issue and assign it to fellow developers, fix an existing issue by going through its details, create “milestones” comprising one or more issues (a milestone is be a set of features to be achieved in a certain timeline). Issues can be viewed from “Issues” tab in your repo’s page.
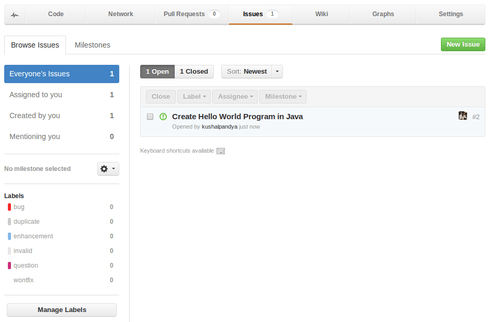
You can add labels to issues depending on its category, see who’s assigned with that issue (a person supposed to fix it), or you can close the issue. You can create new issue simply by clicking its button.
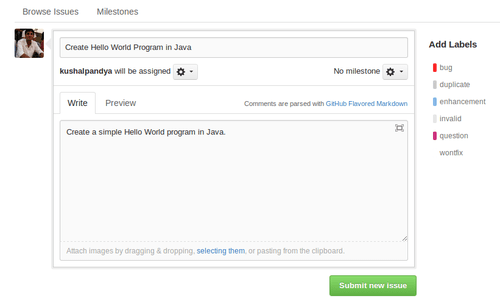
Note that each issue has a unique ID available, which can be used wisely. Not long ago, GitHub added the ability to close an issue just by including its ID within commit message as “fix #12” or “fixes #12”. When this commit is pushed into repository on GitHub, issue with ID 12 is automatically closed, pretty handy.
Other Powerful Features of GitHub
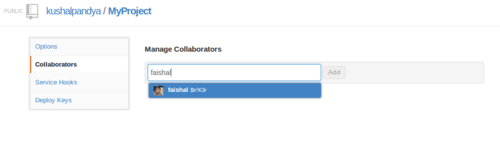
What if you are working on a project where each developer need to have a full access to one common repository? You can add “collaborators” in repository from Settings tab and he’ll get full access to your repository (unlike forking, where a user has only read access).
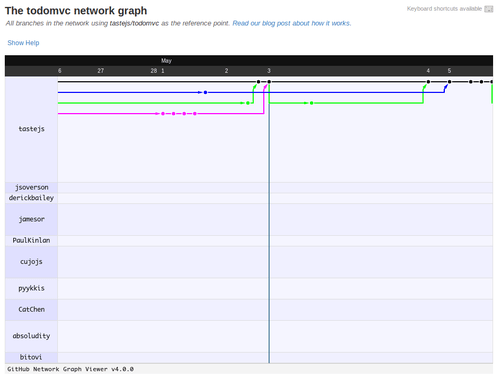
Branches are great and you can view all the branches that have been created in a particular repository from its “Network” tab. Where it shows form where a new branch is created, what is committed by whom in the branch (by hovering over the dots on lines).
You can even see statistics of how developers are working on the project, frequency of commits, top contributors, etc.
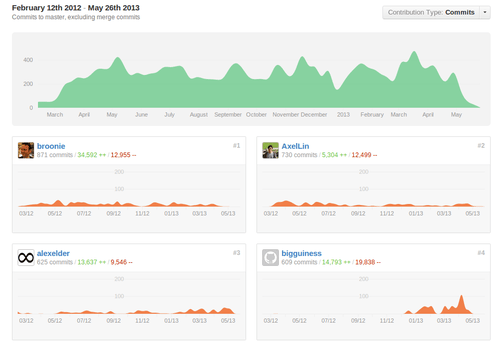
You can also create so-called Wiki Pages for a repository (from Wiki tab) which provides rich documentation about the project (markdown formatted text). If you’re a large team working on multiple projects, you can create “Organizations” on GitHub and add members to it such that each member has access to all the repos created within the organization. And apart from these great built-in features. GitHub has many apps (called “Service Hooks”) available which are tailored for certain tasks. Also, be sure to checkout GitHub Help which covers wide range of topics that you need to know.
Remember I mentioned earlier that by default all repositories that you create on GitHub are public and you need to buy
private repositories if you want to keep your code private? Well, if you’re a student, you can claim 5 free repositories
for 2 years by requesting GitHub Educational Account. Don’t worry, you’ll not have to create a
new account, just visit the link and verify that you’re a student. Happy coding. ![]()